
Introduction
In the 21st century, data has emerged as one of the most valuable resources in the global economy. Often described as “the new oil,” data fuels innovation, economic growth, and decision-making across nearly every sector, from healthcare and finance to governance and entertainment. Like oil during the Industrial Revolution, data powers modern technologies such as artificial intelligence (AI), machine learning, and digital platforms. Companies that control large volumes of data dominate markets, while nations that effectively harness data gain strategic advantages.
However, the comparison between data and oil is not merely about value. Oil brought prosperity but also environmental degradation, geopolitical conflict, and economic inequality. Similarly, data presents immense benefits alongside serious dangers, including privacy erosion, surveillance, monopolization, and widening global inequalities. As societies increasingly rely on data-driven systems, it becomes critical to examine both the opportunities and risks associated with this new resource.
This essay explores the concept of data as the new oil by examining the development divide it creates, the opportunities and challenges it presents, strategies for balanced growth, relevant policy frameworks and historical context, real-world case studies, and recommendations for policy prioritization. The aim is to provide a holistic understanding of how data can be harnessed responsibly for inclusive and sustainable development.
If Data is The New Oil, AI is The Ultimate Refinery
The phrase “Data is the new oil” has become a popular metaphor to highlight the immense value that data holds in modern organizations. And just as oil in its crude form, it requires refining to unlock its true potential.
Raw data needs to be processed and analyzed to extract meaningful insights and drive informed decision-making. This is where Artificial Intelligence (AI) comes into play. AI acts as the ultimate data refinery, giving us the potential of transforming vast amounts of information into actionable insights.
Over the past few years, AI – and in particular Machine Learning (ML) – has been widely applied to process data and extract insights. However, the emergence of Large Language Models (LLMs) has revolutionized the field, leading to the development of numerous new tools designed to enhance data processing capabilities. This evolution requires us to revisit and rethink our data strategy to stay ahead in the rapidly changing landscape.
However, shifting to new AI paradigms is neither easy nor inexpensive. Just as an oil refinery requires significant infrastructure and investment, so too does the effective implementation of AI technologies.
Organizations must invest in the right tools, platforms, and expertise to build a robust and flexible data processing framework. Additionally, they must navigate the complexities of data security and privacy, ensuring that sensitive information is protected at all stages of the refining process.
In this blog post, we will explore how we harness valuable Service Management data with AI at InvGate, discuss the necessary infrastructure investments, and address the challenges of managing data securely. Additionally, we’ll explore the traditional ML data refinement pipeline, and address the ways in which it can be enhanced with LLMs.
The nature and value of data
Data has emerged as one of the most valuable assets for modern organizations. It is reshaping industries by enabling smarter decision-making and new business models.
Organizations collect a wide variety of information, ranging from customer feedback to IoT sensor readings. This data can be categorized into two main types: structured and unstructured. Understanding them is crucial for effectively harnessing their potential.
Unstructured data, such as customer feedback, usually consists of free text that lacks a predefined format but may hold highly valuable insights. LLMs can be very effective at processing this type of data.
Structured data, like IoT device metrics, is highly organized and easily searchable (e.g., devices currently connected to your network). Traditional ML techniques are usually enough to process this type of data.
For instance, in the realm of Service Management, data plays a pivotal role. Analyzing information can enable predictive maintenance scheduling for devices, preventing potential failures and reducing downtime.
It can also facilitate the quick detection of anomalies and major incidents, allowing for faster resolution and minimizing the impact on business operations. Additionally, data-driven insights can enhance root cause analysis of recurrent incidents, leading to more effective problem-solving and continuous improvement in service delivery.
The true value of data lies in its potential to fuel actionable insights. By analyzing it, organizations can uncover hidden patterns, predict future trends, and make informed decisions.
The traditional data refinement pipeline: Turning data into value with ML
No matter how valuable the data, its sole existence is not enough to be data-driven. For that to happen, organizations need to create a data refinement pipeline, where information is ingested, processed, stored, and analyzed. Let’s take a look at the technical components needed to turn data into value.
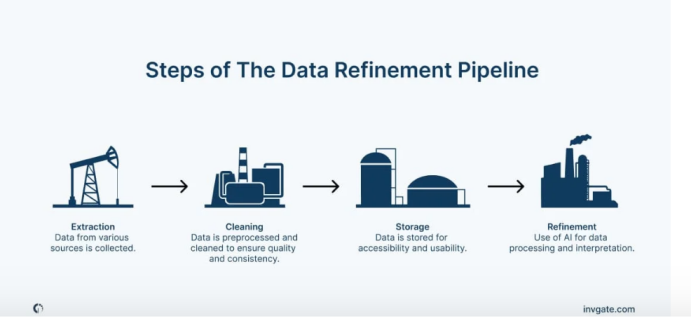
Data ingestion and storage
The first step in the data refinement pipeline is data ingestion, where data from various sources is collected and stored. This stage is crucial for ensuring that the information is both accessible and usable for downstream processes.
At this stage, two types of solutions are needed:
Data orchestration tools: Technologies like Apache Airflow allows us to orchestrate multiple data sources to ensure a smooth and automated flow of the data into different stages of the data refinement pipeline.
Data lakes and warehouses: Data lakes provide a scalable repository for storing structured and unstructured data. Meanwhile, data warehouses (like Amazon Redshift) offer optimized solutions for resolving complex queries.
Data preprocessing and cleaning
Before data can be analyzed, it must be preprocessed and cleaned to ensure quality and consistency. For instance, structured data might contain missing values or multiple nomenclatures for the same things. On the other hand, unstructured data may have duplicates or even text encoding issues. Feeding data directly to the AI models without filtering these sorts of “impurities”, may degrade their outputs’ quality.
To get rid of inconsistencies in the data several techniques are normally used, including:
Data cleaning: ML algorithms can be used to detect and correct anomalies, handle missing values, and remove duplicates.
Data transformation: Techniques such as normalization, encoding, and scaling are applied to prepare data for analysis.
Feature engineering: This step involves creating new features from raw data that can improve model performance. Techniques like one-hot encoding, binning, and embeddings are commonly used.
AI model training
With clean data, the next phase involves training AI models. This stage requires significant computational resources and specialized tools, such as:
ML frameworks: Frameworks like PyTorch and scikit-learn provide the necessary libraries and tools for developing and training ML models. These frameworks support a wide range of algorithms, from linear regression to deep learning.
Compute resources: Training AI models (especially deep learning models) requires powerful computational infrastructure. Cloud-based GPU and TPU instances (offered by providers like AWS, Google Cloud, and Azure) deliver the necessary processing power to handle large-scale model training efficiently.
Hyperparameter tuning: Optimizing model performance involves tuning hyperparameters, using techniques such as grid search and Bayesian optimization.
Model validation: Cross-validation techniques, such as k-fold cross-validation, are used to evaluate model performance and prevent overfitting. These techniques ensure that the model generalizes well to unseen data.
AI model deployment and monitoring
Once a model is trained and validated, it needs to be deployed into production and continuously monitored to ensure its effectiveness.
The steps involved in this stage include:
Model serving: Tools like TorchServe, and cloud-based services like AWS SageMaker Endpoint facilitate the deployment of models as RESTful APIs, enabling real-time predictions.
Containerization and orchestration: Containerization technologies (such as Docker) and orchestration platforms (like Kubernetes) streamline the deployment process, ensuring that models can be scaled and managed efficiently in production environments.
Monitoring and maintenance: Continuous monitoring is essential to ensure that models perform well over time. Retraining pipelines can be automated to update models with new data, ensuring they remain relevant and accurate.
Beyond Traditional ML: Simplifying AI Training for Better Outcomes
Up to now, we have described what can be called “the traditional ML pipeline.” But, in order to leverage the advantages of LLMs, this needs to be updated.
While traditional ML pipelines remain valuable in many domains, LLMs have opened up new and exciting possibilities in data processing and interpretation. This novel approach unlocks a potential that was previously out of reach, allowing us to leverage AI with little to no training.
LLMs like GPT-4, Claude-3, and Llama-3 are at the forefront of this shift, changing how we interact with and understand information.
The key to these models’ versatility lies in their extensive pre-training. Unlike earlier AI models that need extensive training on specific datasets, these advanced LLMs come pre-trained on a vast and diverse collection of data. This comprehensive foundation allows LLMs to handle a wide range of tasks with impressive flexibility and insight.
To leverage these powerful models effectively, several key techniques have emerged: zero-shot and few-shot learning, fine-tuning, and retrieval augmented generation.
Zero-shot and few-shot learning
LLMs are designed to generalize from very few examples or even none at all. This capability is particularly useful for rapid prototyping and in scenarios where data collection is challenging.
Zero-shot learning: The LLM performs tasks without any specific training examples, relying on its pre-trained knowledge to make inferences.
Few-shot learning: The LLM is provided with a limited number of examples, allowing it to adapt quickly to new tasks with minimal data.
LLM fine-tuning
Leveraging pre-trained models through fine-tuning significantly reduces the time and resources required for training. These models can be fine-tuned for specific tasks with relatively small datasets. This approach enables organizations to quickly adapt state-of-the-art models to their unique needs without the need for extensive computational resources.
A key benefit of fine-tuning over full model training is the substantial improvement in performance and accuracy for specific tasks. By starting with a pre-trained model, which has already learned a wide range of features and patterns from a vast dataset, fine-tuning allows for more precise adjustments to be made based on the nuances of a particular task.
This process not only enhances the model’s effectiveness in specialized contexts but also helps mitigate issues related to overfitting, as the knowledge embedded within the pre-trained model provides a robust starting point.
Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) is an innovative approach that empowers the strengths of generative models by allowing them to search for additional information. RAG models retrieve relevant documents or information from a large corpus and use this retrieved data to generate more accurate and contextually relevant responses.
RAG enhances the accuracy and relevance of generated responses, making them particularly useful for tasks requiring up-to-date information or detailed knowledge. For instance, Knowledge Management and customer support are some areas where RAG can significantly improve performance and user satisfaction, providing a conversational interface to search results that allows follow up questions.
Unlike fine-tuned models, which rely solely on their pre-existing knowledge, models using RAG actively retrieve and integrate relevant documents or data from a dynamic corpus during the generation process. This enables models to generate responses that are not only accurate but also dynamically up-to-date.
Challenges in handling and securing data
It’s important to remember that harnessing AI’s potential comes with its own set of challenges, particularly in handling and securing data. As organizations process vast amounts of information, ensuring data privacy, security, and compliance is crucial.
Data privacy concerns
The importance of data privacy cannot be overstated. Organizations must navigate regulations like GDPR and CCPA, which mandate stringent data handling requirements. Techniques such as anonymization and pseudonymization can mitigate privacy risks by protecting identities while allowing data analysis.
Ethical considerations
Compliance with data protection laws is both a legal and ethical obligation. Organizations must ensure fairness, transparency, and accountability in their data practices. This involves being transparent about data usage, obtaining informed consent, and allowing individuals to exercise their data rights.
Data security measures
Securing data against breaches and cyberattacks is a top priority. Key measures include:
Encryption: Protecting data both at rest and in transit using AES and SSL protocols.
Access controls: Limiting data access to authorized personnel through Role-Based Access Control (RBAC) and Attribute-Based Access Control (ABAC).
Data retention policies: Storing data only as long as needed and discarding outdated information to reduce exposure risks.
Regular audits and monitoring: Continuous monitoring and regular security audits using tools like Intrusion Detection Systems (IDS) and Security Information and Event Management (SIEM) platforms.
By prioritizing data privacy, adhering to ethical practices, and implementing robust security measures, organizations can build a trustworthy data infrastructure, fostering customer trust and supporting AI-driven growth.
Embracing AI as the ultimate refinery
AI serves as the ultimate refinery, transforming raw data into invaluable business insights. This journey, though complex, offers immense rewards, from optimizing operations to driving innovation. LLMs can significantly enhance this process by reducing training costs and complexity, unlocking insights that were previously unattainable.
While AI’s benefits are clear, addressing data privacy and security is crucial. Implementing robust security measures and ensuring transparency in AI models build trust and compliance. By proactively tackling these challenges, organizations can harness AI’s power while safeguarding data integrity.
Embracing AI is not just a technological shift but a strategic imperative. Converting raw data into actionable insights drives growth and efficiency. As AI and cloud computing evolve, they make advanced AI capabilities more accessible and scalable. Organizations that invest in the right AI infrastructure, prioritize data security, and stay ahead of technological advancements will unlock the full potential of their data assets.
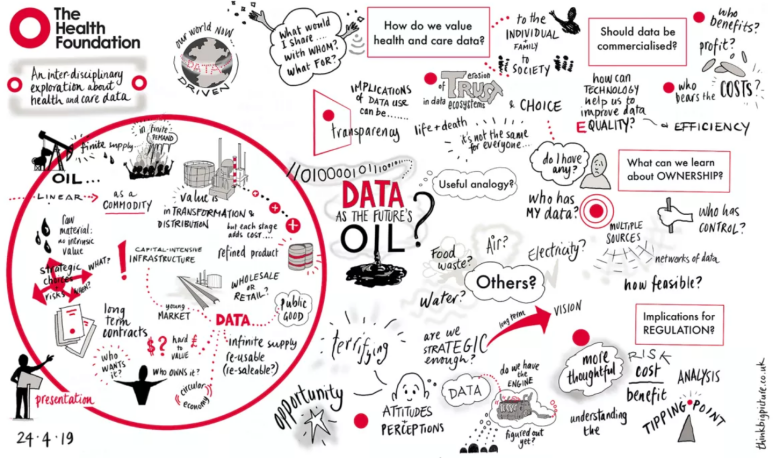
Analogies matter. They allow us to make sense of complex ideas. They also influence our thinking in ways that we don’t fully understand and might not be conscious of. But how often do we examine the analogies that we are using, to really explore the ideas we are conveying?
We’ve all heard that data is the new oil. It’s an easy comparison to make and on a superficial level, it makes sense. The phrase has become widely accepted since it was coined, seemingly by the architect of Tesco’s Clubcard, and then popularised by the Economist. Two years ago they published an article entitled, ‘The world’s most valuable resource is no longer oil, but data’.
There has been pushback since, with Antonio García Martínez writing in Wired that it is ‘supremely unhelpful to perpetuate the analogy’. I myself had previously written about data being the oil of the digital age, but without being able to really unpick what this means – what’s helpful, what’s not, what assumptions underlie this analogy and what impact does it have on our thinking more generally?
At the Health Foundation, we’ve been using data for some time to tackle problems in health care. We are now also exploring what more we can do to ensure that data and technology have a positive impact on our health. To help us develop our thinking, we held a roundtable on this oil analogy, inviting data leaders from UK health care as well as other sectors. Energy markets expert Katherine Spector was a guest speaker. As a research scholar at the Center on Global Energy Policy at Columbia University, she knows the oil and natural gas markets inside out. The roundtable was a great opportunity for us to explore the analogy that has become so pervasive in our thinking, and our visual scribe did a good job of capturing our discussions.
Where the oil analogy is helpful
Like oil, data is worthless in its raw form, but requires refinement, cleaning, structuring and amalgamation. Also like oil, data has a multiplicity of end uses, including algorithms to detect eye disease from images, approaches to help busy hospitals respond to winter pressures and insights from randomised registry trials.
These parallels give us a glimpse of one future for the data system. The oil industry has invested in refineries to transform crude oil into more useful products. Do we need data refineries?
There are lessons from the oil industry. They have placed big bets on infrastructure, but some of their investments have become rapidly outdated, as new products have become available that have shifted what is needed. It’s likely that over the next few years we will discover new uses for data. We will therefore need our data infrastructure to be flexible.
This is a big challenge to the ‘data refineries’ currently being built, including the National Commissioning Data Repository, DRIVE and the Digital Innovation Hubs. The emphasis from NHSX on open standards will help, though we probably need more investment in the data managers, architects and engineers who will lead the refinement process.
Of course, there are negative environmental effects from oil (eg spills, fracking, burning petrol and waste plastics). We have become more aware of and more responsive to these ill effects. Likewise, we are becoming more aware of the negative impacts of data – such as the risk of harmful data leaks and the potential for algorithms to automate injustices. Maybe the data community can learn from the approaches that governments have taken to address the negative consequences of oil use (including taxes and plastic bag charges), while acknowledging their limitations.
The Indian Refinery: Distilling Data into Disruption
Crude oil is useless without refineries to distil it into petrol, plastic, and chemicals. Similarly, India’s raw data is being processed in sophisticated “refineries”—the algorithms of its tech startups, the analytics departments of its legacy corporations, and the policy-making engines of its government.
This is where data science cleans, processes, and analyses the raw data to create actionable insights—the high-octane fuel of the new economy.
Distillation in Finance: For decades, a large segment of the Indian population was “unbanked,” invisible to the formal financial system. Companies like CRED and Razorpay are acting as refineries. They analyse transaction data from UPI and credit cards to build sophisticated credit-scoring models. They can “distil” your payment history into a reliable measure of creditworthiness, offering loans to millions of new-to-credit individuals and small businesses that traditional banks would have rejected. The crude data of a digital payment is refined into the fuel of financial inclusion.
Cracking in Agriculture: The agrarian sector, the backbone of India, is being transformed. Ninjacart, a B2B agri-tech platform, acts as a massive data refinery. It analyses data on crop yields, weather patterns, soil health, and real-time demand across cities. By “cracking” this complex dataset, it can predict exactly which vegetables will be needed in Bangalore tomorrow, instructing farmers in Tamil Nadu on what to harvest today. This reduces waste, increases farmer income, and stabilises prices—turning agricultural data into the fuel for a more efficient supply chain.
Transformation in Healthcare: Startups like Practo and Tata1mg are refining the chaotic data of India’s healthcare system. They aggregate data on doctor availability, patient reviews, diagnostic test results, and medicine availability. This refined insight allows a user in a tier-2 city to find a specialist, book an appointment, get lab tests done, and order medicines seamlessly. The crude data of clinic schedules and medicine inventories is transformed into the fuel for accessible, efficient healthcare.
Fuelling a New Economic Engine
Just as oil powered the industrial revolution, data is fuelling India’s entrepreneurial and economic boom. The most valuable Indian startups are not in heavy industry, but in data-centric domains.
– Ola Cabs uses traffic, ride, and location data to optimise routes, set dynamic pricing, and even guide the development of its electric vehicles.
– Swiggy doesn’t just deliver food; it refines order data to predict demand, optimise delivery partner routes, and even advise restaurants on their menus, creating a hyper-efficient logistics network.
– Byju’s analyses student interaction data to personalise learning paths, identifying knowledge gaps and adapting content in real-time, refining clickstream data into the fuel for educational outcomes.
These companies, and hundreds like them, are the new economic giants, built not on physical assets, but on the refined fuel of data-driven insight.
I. Development Divide
One of the most significant consequences of the data revolution is the widening development divide between countries, regions, and social groups. Just as oil-rich nations gained economic and political power in the 20th century, data-rich nations and corporations now hold disproportionate influence in the global economy.
Developed countries possess advanced digital infrastructure, high internet penetration, skilled human capital, and strong research ecosystems. These advantages allow them to collect, process, and monetize vast amounts of data. In contrast, many developing countries lack reliable internet access, data storage capabilities, and regulatory frameworks, limiting their ability to benefit from the data economy. This disparity leads to what is often called the “digital divide,” which reinforces existing inequalities.
At the corporate level, large technology companies dominate data ownership. Platforms such as search engines, social media networks, and e-commerce sites collect massive datasets from users worldwide. Smaller firms and startups struggle to compete because they lack access to comparable data resources. This concentration of data mirrors the monopolistic tendencies of oil conglomerates in the past.
Socially, the development divide also affects individuals. Those with digital literacy, access to smart devices, and online presence generate and benefit from data-driven services, while marginalized communities risk being excluded or exploited. Thus, the data economy can deepen inequalities unless deliberate efforts are made to ensure equitable access and participation.
II. Opportunities and Challenges
Opportunities
The benefits of data are extensive and transformative. In healthcare, data analytics enables early disease detection, personalized treatment, and efficient health system management. During global health crises, data-driven tracking systems help monitor outbreaks and allocate resources effectively.
In economic development, data improves productivity by optimizing supply chains, enhancing customer experiences, and supporting innovation. Governments use data to design evidence-based policies, improve public service delivery, and increase transparency. Smart cities leverage data to manage traffic, energy consumption, and public safety more efficiently.
Education has also been reshaped by data. Learning analytics allow educators to tailor instruction to individual needs, improving outcomes. In agriculture, data-driven technologies help farmers predict weather patterns, optimize crop yields, and reduce waste.
Challenges
Despite these opportunities, data poses serious challenges. Privacy is one of the most pressing concerns. Personal data is often collected without informed consent and used in ways individuals do not fully understand. Data breaches and misuse can lead to identity theft, discrimination, and loss of trust.
Surveillance is another major danger. Governments and corporations can use data to monitor behavior, suppress dissent, or manipulate public opinion. The rise of algorithmic decision-making raises concerns about bias, as flawed or unrepresentative data can reinforce social inequalities.
Economic challenges include market concentration and unfair competition. When data becomes the primary asset, companies with the most data gain overwhelming advantages, stifling innovation and competition. Additionally, cross-border data flows raise questions about data sovereignty and national security.
III. Strategies for Balanced Development
To ensure that data serves as a force for inclusive development rather than exploitation, balanced strategies are essential. First, digital infrastructure must be expanded, particularly in developing regions. Affordable internet access, cloud computing, and data centers are foundational to participation in the data economy.
Second, capacity building is critical. Governments and institutions should invest in digital literacy, data science education, and technical training. Empowering individuals with the skills to understand and use data reduces dependency on external actors and promotes local innovation.
Third, ethical data governance should be prioritized. Transparency, accountability, and fairness must guide data collection and use. Organizations should adopt principles such as data minimization, informed consent, and explainable algorithms.
Finally, collaboration between governments, private sector actors, academia, and civil society can help balance interests. Public–private partnerships can support innovation while ensuring public oversight and social responsibility.
IV. Policy Frameworks and Historical Context
The idea of regulating a powerful resource is not new. During the oil era, governments introduced policies to manage extraction, taxation, environmental protection, and market competition. Lessons from this history are highly relevant to data governance.
Early industrialization showed that unregulated resource exploitation leads to inequality and environmental harm. Over time, labor laws, antitrust regulations, and environmental standards were introduced to mitigate these effects. Similarly, data requires robust policy frameworks to prevent abuse and ensure fair distribution of benefits.
Modern data policies include data protection laws, cybersecurity regulations, and competition policies. Frameworks such as data localization, cross-border data agreements, and digital trade rules aim to balance economic growth with national interests and individual rights.
However, policy development often lags behind technological change. The global nature of data complicates regulation, as data flows easily across borders while laws remain nationally defined. This makes international cooperation essential for effective governance.
V. Case Studies in Integrated Development
Several real-world examples illustrate both the promise and risks of data-driven development. One notable case is the use of data in digital governance initiatives. Countries that have implemented digital identification systems have improved access to public services, reduced corruption, and enhanced administrative efficiency. At the same time, concerns about surveillance, data security, and exclusion highlight the need for safeguards.
In the private sector, data-driven companies have transformed industries such as transportation, finance, and retail. Ride-sharing platforms, for example, use data to optimize routes and pricing, creating convenience for users and new income opportunities. However, these platforms also raise issues related to labor rights, data ownership, and market dominance.
In agriculture, data integration through satellite imagery and mobile technology has improved productivity and resilience, particularly for small farmers. When combined with supportive policies and local participation, data can empower communities rather than exploit them.
These case studies demonstrate that integrated development—where technology, policy, and social considerations align—can maximize benefits while minimizing harm.
VI. Recommendations for Policy Prioritization
To harness data responsibly, policymakers should prioritize several key areas. First, strong data protection laws are essential to safeguard privacy and build public trust. These laws should clearly define data ownership, consent, and accountability.
Second, competition policy must address data monopolies. Antitrust regulations should prevent excessive concentration of data and promote fair access for smaller firms and innovators. Data-sharing frameworks, where appropriate, can level the playing field.
Third, international cooperation should be strengthened. Global standards for data governance, cybersecurity, and ethical AI can reduce regulatory fragmentation and prevent exploitation.
Fourth, inclusion must be a central goal. Policies should ensure that marginalized groups benefit from the data economy through targeted investments, education, and access programs.
Finally, continuous evaluation and adaptation of policies are necessary. As technology evolves, regulatory frameworks must remain flexible and responsive.
Conclusion
The metaphor “data is the new oil” captures the immense value and transformative power of data in the modern world. Like oil, data drives economic growth, innovation, and geopolitical influence. Yet, it also carries significant dangers, including inequality, privacy erosion, and concentration of power.
The challenge for societies today is not merely to extract and exploit data, but to govern it wisely. By learning from historical experiences with other critical resources, adopting balanced strategies, and implementing robust policy frameworks, data can be harnessed for inclusive and sustainable development.
Ultimately, data should serve humanity, not the other way around. With thoughtful governance, ethical practices, and global cooperation, the benefits of data can be shared broadly while minimizing its risks—ensuring that this new oil fuels progress rather than division.
The “data as the new oil” metaphor is compelling because it captures the essence of a resource-driven transformation. However, India’s journey shows one critical difference: oil is a finite resource that depletes with use. Data is an infinite resource that multiplies with use. Every transaction generates more data, which in turn improves the models, leading to better services, which then attract more users and generate even more data—a virtuous cycle of creation.
India is uniquely positioned in this new economy. It possesses a massive, diverse, and growing data oilfield, a young and tech-savvy population to build the refineries, and a regulatory framework that is evolving in real-time. The challenge is no longer about collecting the crude; it’s about building ethical, efficient, and innovative refineries. For India, data is not just the new oil; it is the national project of the 21st century, the fuel that will power its ascent on the global stage. The drilling has begun, the refineries are humming, and the nation is accelerating into a future built on bits and bytes.